Evolutionary Algorithms
Basic principles of Evolutionary Algorithms (EAs, among which the best known are Genetic Algorithms) model some biological phenomena, and more precisely the ability of populations of living organisms to adapt to their environment, via genetic inheritance and Darwinian strife for survival. Resolution methods and stochastic optimisation methods have been designed according to these - of course, extremely simplified - biologically-inspired principles, and give birth to the so-called "Artificial Darwinism".
The main characteristic of EAs is that they manipulate populations of points of the search space, and involve a set of operations applied (stochastically) to each individual of the population, organised in generations of the artificial evolution process. Operations involved are of two types : selection , based on the individuals' performance w.r.t. the problem being solved and genetic operators , usually crossover and mutation , that produce new individuals. If correctly designed, a dynamic stochastic search process is started on the search space that converges to the global optimum of the function to be optimised (A large part of EA theoretical research addresses this convergence problem, as well as understanding of the notion of EA-difficulty, i.e. what makes the job difficult for an EA).
From the point of view of optimisation, EAs are powerful stochastic zero order methods (i.e., requiring only values of the function to optimise) that can find the global optimum of very rough functions. This allows EAs to tackle optimisation problems for which standard methods (e.g., gradient-based algorithms requiring the existence and computation of derivatives) are not applicable.
Despite the apparent simplicity of an EA process - which has driven many programmers to first write their own EA adapted to their specific problem - building an efficient EA for an application is a rather tricky task. In fact, EAs are very sensitive to parameter settings and design choices.
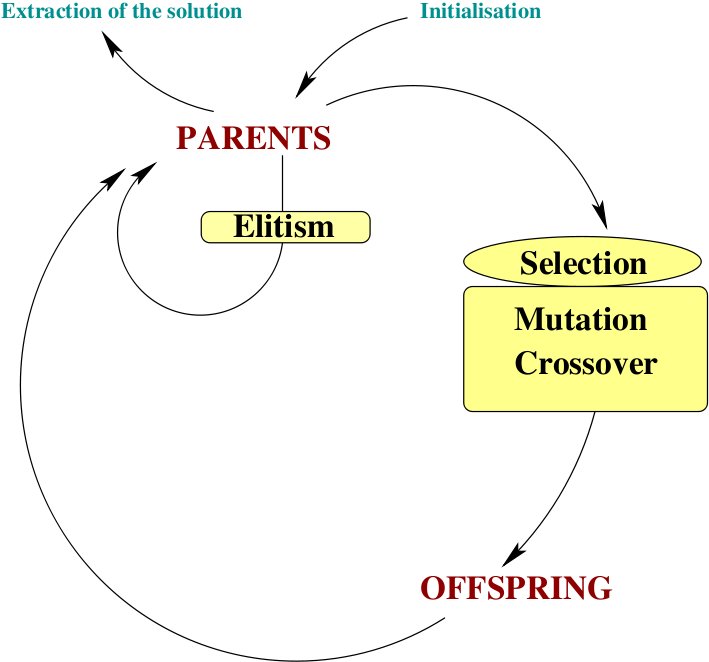
The basic ingredients of a ``canonical'' evolutionary algorithm are succinctly described below. This structure is only a framework, an efficient EA application to a specific problem may be far more complex.
The generation loop starts from a population of individuals (which contain a genome, i.e. a collection of parameters (genes) representing a potential solution) usually named parents.
Selection: This step selects which parents are going to reproduce. This operation is based on an evaluation of the quality of the individual using a fitness function which is thus maximised during the evolution of the EA. Usually, two parents giving birth to two offsprings, the number of selected parents is equal to the number of desired offsprings.
Reproduction: The selected parents are randomly paired. Each pair then mates to create two children, with a certain probability for a crossover function to be called on the parents' genes. Then each child (resulting from a crossover, or a non-crossover between selected parents) either undergoes a mutation (also with a certain probability). The resulting individuals are called the offsprings.
Evaluation: The population of offsprings is evaluated by the fitness function.
Replacement: This step is used to create the population of parents for the future generation by selecting from the pool of offsprings + parents which of them will survive (the others are discarded and disappear).
Stopping criterion: At some point, the algorithm stops, depending on user-defined criteria (total number of generations, fitness threshold on the best individual, ...)
|
|